在大數(shù)據(jù)時代,高效、可靠的數(shù)據(jù)管理技術(shù)是企業(yè)信息化建設(shè)的核心。HBase作為一項關(guān)鍵技術(shù),其價值不僅在于自身,更在于它所處的龐大系統(tǒng)生態(tài)——Hadoop,以及它在復(fù)雜信息系統(tǒng)集成中所扮演的角色。本文將深入剖析HBase在Hadoop生態(tài)系統(tǒng)中的定位,并探討圍繞其進行系統(tǒng)集成時可提供的技術(shù)咨詢要點。
一、HBase在Hadoop生態(tài)系統(tǒng)中的核心定位
Hadoop生態(tài)系統(tǒng)是一個功能豐富、組件協(xié)同的分布式計算與存儲平臺。HBase在其中扮演著“分布式、可伸縮、面向列的大數(shù)據(jù)存儲引擎”這一關(guān)鍵角色,其定位具體體現(xiàn)在:
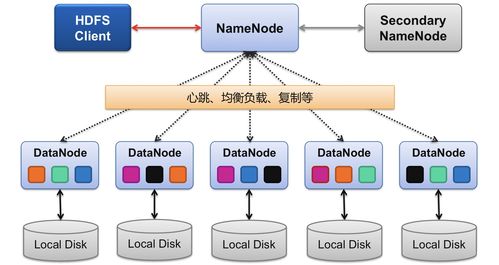
- 存儲層的互補與增強:HBase構(gòu)建在Hadoop分布式文件系統(tǒng)(HDFS)之上。HDFS擅長存儲海量非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù),并提供高吞吐量的順序讀寫,但其隨機讀寫能力較弱。HBase則彌補了這一短板,它利用HDFS的可靠存儲,在其上構(gòu)建了一個支持低延遲、強一致性隨機讀寫(尤其是基于行鍵)的數(shù)據(jù)庫。二者結(jié)合,形成了“HDFS負責(zé)底層海量持久化,HBase負責(zé)上層高效數(shù)據(jù)訪問”的經(jīng)典分層存儲架構(gòu)。
- 與計算框架的無縫集成:HBase與Hadoop的計算框架MapReduce,以及后來的Spark、Flink等深度集成。這些計算框架可以直接將HBase表作為數(shù)據(jù)源(Input)或數(shù)據(jù)匯(Output),進行復(fù)雜的數(shù)據(jù)批處理或流處理分析。這種集成使得海量數(shù)據(jù)的存儲(HBase)與計算(MapReduce/Spark)能夠在同一集群內(nèi)高效協(xié)同,避免了不必要的數(shù)據(jù)移動,極大提升了數(shù)據(jù)處理的效率。
- 實時查詢的支撐者:在Lambda或Kappa等大數(shù)據(jù)架構(gòu)中,HBase常被用作“服務(wù)層”或“批視圖”的存儲。經(jīng)過批處理或流處理加工后的結(jié)果,可以實時寫入HBase,供前端應(yīng)用進行低延遲的隨機查詢和檢索,從而滿足在線業(yè)務(wù)系統(tǒng)的實時性需求。
- 生態(tài)組件的樞紐:HBase與Hadoop生態(tài)的其他組件(如Hive, Phoenix, Solr)緊密協(xié)作。例如,通過Apache Phoenix可以在HBase上提供SQL查詢接口;通過與Apache Solr集成,可以實現(xiàn)全文搜索功能。這些集成進一步拓展了HBase的應(yīng)用邊界,使其從一個存儲引擎升級為一個多功能的數(shù)據(jù)服務(wù)平臺。
二、圍繞HBase的信息系統(tǒng)集成與技術(shù)咨詢要點
將HBase集成到企業(yè)現(xiàn)有或新建的信息系統(tǒng)中是一項系統(tǒng)工程,涉及架構(gòu)設(shè)計、數(shù)據(jù)治理、運維保障等多個層面。專業(yè)的技術(shù)咨詢應(yīng)涵蓋以下關(guān)鍵點:
- 適用場景評估與架構(gòu)設(shè)計咨詢:
- 明確適用性:并非所有場景都適合HBase。咨詢需首先幫助客戶判斷:數(shù)據(jù)量是否達到TB/PB級?是否需要高并發(fā)隨機讀寫?數(shù)據(jù)模型是否適合寬表、稀疏的列式存儲?是否要求強一致性?明確HBase最適合的場景,如用戶畫像、實時訂單查詢、消息日志存儲、時空數(shù)據(jù)等。
- 架構(gòu)規(guī)劃:設(shè)計HBase集群與現(xiàn)有系統(tǒng)(如業(yè)務(wù)數(shù)據(jù)庫、消息隊列、ETL工具)的集成架構(gòu)。包括數(shù)據(jù)如何從源系統(tǒng)流入HBase(通過Kafka, Flume, Spark Streaming等),應(yīng)用層如何訪問HBase(使用原生API、Phoenix或中間件),以及如何與下游的分析、報表系統(tǒng)對接。
- 數(shù)據(jù)模型與Schema設(shè)計咨詢:
- 行鍵設(shè)計:這是HBase性能的關(guān)鍵。需指導(dǎo)設(shè)計具有良好散列性、能反映訪問模式的行鍵,避免熱點問題。同時考慮前綴掃描等查詢需求。
- 列族與版本規(guī)劃:根據(jù)數(shù)據(jù)的訪問特點和血緣關(guān)系,合理設(shè)計列族數(shù)量(通常建議少量)。規(guī)劃數(shù)據(jù)版本保留策略,平衡存儲成本與歷史追溯需求。
- 性能調(diào)優(yōu)與容量規(guī)劃咨詢:
- 集群配置:提供硬件配置建議(CPU、內(nèi)存、SSD/HDD選擇),以及HBase核心參數(shù)(如Region大小、MemStore大小、阻塞策略等)的調(diào)優(yōu)指導(dǎo)。
- 容量與擴展性:指導(dǎo)客戶根據(jù)數(shù)據(jù)增長率和訪問量預(yù)測,進行集群規(guī)模規(guī)劃。明確水平擴展(增加RegionServer)的方案和操作流程。
- 高可用、安全與運維管理咨詢:
- 高可用保障:闡述HBase基于HDFS副本、RegionServer故障自動恢復(fù)、Master高可用等機制。設(shè)計容災(zāi)備份方案(如Snapshot、Replication)。
- 安全集成:指導(dǎo)如何與Kerberos、Apache Ranger等安全框架集成,實現(xiàn)認證、授權(quán)和審計。
- 監(jiān)控與運維:推薦監(jiān)控指標體系(如集群負載、請求延遲、Compaction情況),搭建監(jiān)控告警系統(tǒng)(如集成Prometheus/Grafana)。制定日常運維、問題診斷和升級擴容的標準操作流程(SOP)。
- 與混合技術(shù)棧的集成咨詢:
- 在微服務(wù)架構(gòu)中,指導(dǎo)如何將HBase作為微服務(wù)背后的數(shù)據(jù)存儲之一,并通過API網(wǎng)關(guān)或服務(wù)層進行封裝。
- 在混合云或多數(shù)據(jù)中心部署中,設(shè)計跨集群的數(shù)據(jù)同步與訪問方案。
結(jié)論
HBase是Hadoop生態(tài)系統(tǒng)中承上啟下的關(guān)鍵組件,它賦予了Hadoop生態(tài)實時交互的能力。成功引入HBase并使其在信息系統(tǒng)中發(fā)揮價值,遠不止于安裝部署,更需要一套從場景適配、架構(gòu)設(shè)計到持續(xù)運維的完整技術(shù)咨詢與實施方法論。理解其在生態(tài)中的定位,是進行有效集成和咨詢的基石。通過專業(yè)的規(guī)劃與設(shè)計,HBase能夠成為企業(yè)構(gòu)建高性能、可擴展大數(shù)據(jù)平臺的核心支柱。